



Gin路由算法模拟
概述
Gin的路由算法是采用压缩字典树实现的,基数树(Radix Tree)又称为PAT位树(Patricia Trie or crit bit tree),是一种更节省空间的前缀树(Trie Tree)。对于基数树的每个节点,如果该节点是唯一的子树的话,就和父节点合并。下图为一个基数树示例:
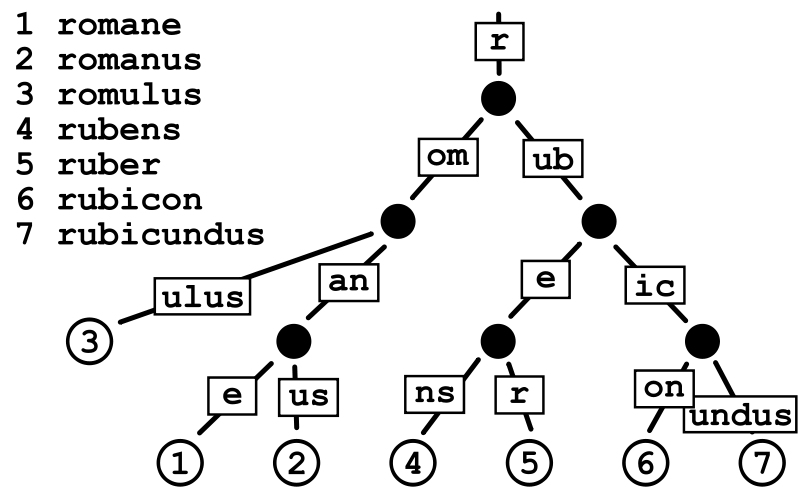
算法模拟
结构体组成:
// TrieNode 压缩字典树节点
type TrieNode struct {
// 存储子节点的索引
indices string
// 存储当前节点的值
value string
// 子节点
children []*TrieNode
}
// NewTrieTree 创建一颗新Trie树
func NewTrieTree() *TrieNode {
return &TrieNode{}
}
新增节点,主要考虑的难点是存在部分共同前缀时需要进行分裂:
// InsertNode 向TireTree中新增节点
func (n *TrieNode) InsertNode(str string) (inserted bool) {
// 如果节点值为空,当前节点为根节点
// 如果当前节点的值和str的前缀完全一致
lenn := len(n.value)
if lenn < len(str) && n.value == str[0:lenn] || n.value == "" {
// 如果前缀不在索引中,加到索引
// 并且由于子节点不存在共同前缀,因此,新增节点
c := str[lenn]
if strings.IndexByte(n.indices, c) == -1 {
// 子节点都不存在共同前缀=>新增节点到当前节点下
n.indices += string(c)
newNode := TrieNode{
indices: "",
value: str[lenn:],
children: nil,
}
if n.children == nil {
n.children = []*TrieNode{
&newNode,
}
} else {
n.children = append(n.children, &newNode)
}
return true
} else if n.children != nil {
// 子节点存在共同前缀:向下寻找子节点进行对比
for _, child := range n.children {
// 如果前缀无法匹配,快速结束
strSub := str[lenn:]
if strSub[0] != child.value[0] {
continue
}
// 向下时裁切掉前缀部分
inserted = child.InsertNode(strSub)
// 快速结束
if inserted {
return
}
}
}
}
// 不存在共同前缀
// 如果存在部分匹配前缀,需要进行分裂,增加新节点
index := FindPrefix(n.value, str)
if index != -1 {
// 当前节点变为共同前缀,向下分裂一个子节点
i := index + 1
p := n.value[0:i]
s := n.value[i:]
s2 := str[i:]
n.value = p
newNode := TrieNode{
// 继承node的索引
indices: n.indices,
value: s,
children: n.children,
}
// 第二个节点
newNode2 := TrieNode{
indices: "",
value: s2,
children: nil,
}
// 更新node的索引
n.indices = s[0:1]
s2Idx := s2[0:1]
if n.indices != s2Idx {
n.indices += s2Idx
}
// 分裂之后,node拥有新的两个节点作为孩子
n.children = []*TrieNode{
&newNode, &newNode2,
}
return true
}
return false
}
节点查找:递归版本
// FindNode 查找字符串在树是否存在
func (n *TrieNode) FindNode(str string) (found bool) {
if str == "" {
return false
}
// 如果当前节点匹配字符串,则匹配,否则匹配前缀,查找索引,向下查找子节点
if str == n.value {
return true
}
lenn := len(n.value)
if len(str) > lenn && str[0:lenn] == n.value && n.children != nil {
// 匹配前缀,查找索引
// 切割去除前缀
str = str[lenn:]
// str的索引
idx := str[0]
// 如果当前node的索引包含 idx
if strings.IndexByte(n.indices, idx) != -1 {
// 存在索引
for _, child := range n.children {
if child.value[0] == idx {
// 加入快速匹配
if child.value == str {
return true
}
// 匹配该子节点,继续向下匹配
found = child.FindNode(str)
// 快速结束
if found {
return
}
} else {
// 该子节点不匹配索引
continue
}
}
}
}
return
}
格式化打印树:
// FormatTree 格式化树结构
// --
// |__ a
// |__ bd
// |__ d
func (n *TrieNode) FormatTree() string {
var buf bytes.Buffer
if n.value == "" {
buf.WriteString("\n-- \n")
} else {
buf.WriteString("|__ " + n.value + "\n")
}
if n.children != nil {
for _, child := range n.children {
childStr := child.FormatTree()
// 增加前缀
// 分割行
sps := strings.Split(childStr, "\n")
for _, sp := range sps {
if sp != "" {
buf.WriteString(" ")
buf.WriteString(sp)
buf.WriteString("\n")
}
}
}
}
return buf.String()
}
非递归版本查找算法:
// FindNode2 查找字符串在树是否存在-非递归版本实现
func (n *TrieNode) FindNode2(str string) (found bool) {
nowNode := n
walk:
if str == "" {
return false
}
// 如果当前节点匹配字符串,则匹配,否则匹配前缀,查找索引,向下查找子节点
if str == nowNode.value {
return true
}
lenn := len(nowNode.value)
if len(str) > lenn && str[0:lenn] == nowNode.value && nowNode.children != nil {
// 匹配前缀,查找索引
// 切割去除前缀
str = str[lenn:]
// str的索引
idx := str[0]
// 如果当前node的索引包含 idx
if strings.IndexByte(nowNode.indices, idx) != -1 {
// 存在索引
for _, child := range nowNode.children {
if child.value[0] == idx {
// 匹配该子节点,继续向下匹配
nowNode = child
goto walk
} else {
// 该子节点不匹配索引
continue
}
}
}
}
return
}
算法性能测试和对比
新增节点的耗时和内存消耗对比,因为gin的节点包含更多信息,所以gin的内存占用是最多的,占用内存最少的是List存储,其次是hashmap,然后是压缩字典树,为什么压缩字典树内存消耗这么多呢,很大程度是因为索引。索引使得每个节点需要存储的信息大大增加。
// 内存占用分析,数量级 1000_0000
// go test -run '^.*InsertNodeMem.*$' -v
// === RUN Test_InsertNodeMem_TrieTree
// testgin2_test.go:165: startMem usage:0 MB
// testgin2_test.go:174: memory usage:1359 MB
//--- PASS: Test_InsertNodeMem_TrieTree (16.03s)
//=== RUN Test_InsertNodeMem_HashMap
// testgin2_test.go:181: startMem usage:1359 MB
// testgin2_test.go:189: memory usage:552 MB
//--- PASS: Test_InsertNodeMem_HashMap (2.29s)
//=== RUN Test_InsertNodeMem_List
// testgin2_test.go:196: startMem usage:1911 MB
// testgin2_test.go:204: memory usage:381 MB
//--- PASS: Test_InsertNodeMem_List (0.84s)
//PASS
//ok mytest/testgin/testgin2 19.585s
//=== RUN Test_InsertNode_GinTree
// testgin2_test.go:369: startMem usage:1 MB
// testgin2_test.go:378: memory usage:2192 MB
//--- PASS: Test_InsertNode_GinTree (16.64s)
var size = 1000_0000
func Test_InsertNodeMem_TrieTree(t *testing.T) {
mem := runtime.MemStats{}
runtime.ReadMemStats(&mem)
startMem := mem.TotalAlloc/MiB
t.Logf("startMem usage:%d MB", startMem)
// 初始化
tree := NewTrieTree()
for i := 0; i < size; i++ {
str := strconv.Itoa(rand.Int())
tree.InsertNode(str)
}
runtime.ReadMemStats(&mem)
curMem := mem.TotalAlloc/MiB - startMem
t.Logf("memory usage:%d MB", curMem)
}
func Test_InsertNodeMem_HashMap(t *testing.T) {
// 初始化
mem := runtime.MemStats{}
runtime.ReadMemStats(&mem)
startMem := mem.TotalAlloc/MiB
t.Logf("startMem usage:%d MB", startMem)
m := make(map[string]bool, size)
for i := 0; i < size; i++ {
str := strconv.Itoa(rand.Int())
m[str] = true
}
runtime.ReadMemStats(&mem)
curMem := mem.TotalAlloc/MiB - startMem
t.Logf("memory usage:%d MB", curMem)
}
func Test_InsertNodeMem_List(t *testing.T) {
// 初始化
mem := runtime.MemStats{}
runtime.ReadMemStats(&mem)
startMem := mem.TotalAlloc/MiB
t.Logf("startMem usage:%d MB", startMem)
l := make([]string, size)
for i := 0; i < size; i++ {
str := strconv.Itoa(rand.Int())
l[i] = str
}
runtime.ReadMemStats(&mem)
curMem := mem.TotalAlloc/MiB - startMem
t.Logf("memory usage:%d MB", curMem)
}
// 复制了一份gin树的算法,测试其性能,gin耗费内存比自己写的TrieTree更多(考虑到其使用了更多属性用于存储数据)
//
//=== RUN Test_InsertNode_GinTree
// testgin2_test.go:369: startMem usage:1 MB
// testgin2_test.go:378: memory usage:2192 MB
//--- PASS: Test_InsertNode_GinTree (16.64s)
func Test_InsertNode_GinTree(t *testing.T) {
mem := runtime.MemStats{}
runtime.ReadMemStats(&mem)
startMem := mem.TotalAlloc/MiB
t.Logf("startMem usage:%d MB", startMem)
// 初始化
tree := &node{}
for i := 0; i < size; i++ {
str := strconv.Itoa(rand.Int())
tree.addRoute(str, []HandlerFunc{func(*gin.Context) {}})
}
runtime.ReadMemStats(&mem)
curMem := mem.TotalAlloc/MiB - startMem
t.Logf("memory usage:%d MB", curMem)
}
对比查找性能:性能不如hashmap也情有可原,毕竟字典树的优点最主要是支持通配符路由,gin的性能不错(因为实现了优先级,查找的平均用时会更短)。但是距离hashmap还有五倍的落后。
每个树级别上的子节点都按Priority(优先级)排序,其中优先级(最左列)就是在子节点(子节点、子子节点等等)中注册的句柄的数量。这样做有两个好处:
首先优先匹配被大多数路由路径包含的节点。这样可以让尽可能多的路由快速被定位。
类似于成本补偿。最长的路径可以被优先匹配,补偿体现在最长的路径需要花费更长的时间来定位,如果最长路径的节点能被优先匹配(即每次拿子节点都命中),那么路由匹配所花的时间不一定比短路径的路由长。下面展示了节点(每个-可以看做一个节点)匹配的路径:从左到右,从上到下。
// 性能测试,查找性能,测试 1000 w数量随机整数,查找任意一个整数
// go test -run '^$' -bench '.*FindNode$' -benchmem
// 可以看到,性能和hashmap相比并无优势,差距达到10倍
// Benchmark_FindNode/TrieTree-24 520750 2454 ns/op 23 B/op 1 allocs/op
// Benchmark_FindNode/HashMap-24 5526843 222.6 ns/op 23 B/op 1 allocs/op
// 优化后:
// Benchmark_FindNode/TrieTree-24 679867 1758 ns/op 23 B/op 1 allocs/op
// Benchmark_FindNode/HashMap-24 5332783 240.9 ns/op 23 B/op 1 allocs/op
// 对比遍历查找,性能无疑好了非常多:
// Benchmark_FindNode/TrieTree-24 686958 1689 ns/op 23 B/op 1 allocs/op
// Benchmark_FindNode/HashMap-24 5461135 221.3 ns/op 23 B/op 1 allocs/op
// Benchmark_FindNode/List-24 25 43738816 ns/op 24 B/op 1 allocs/op
// 对比gin,gin的性能确实不错
//Benchmark_FindNode/TrieTree-24 682962 1794 ns/op 23 B/op 1 allocs/op
//Benchmark_FindNode/HashMap-24 5606622 207.5 ns/op 23 B/op 1 allocs/op
//Benchmark_FindNode/List-24 24 48739212 ns/op 24 B/op 1 allocs/op
//Benchmark_FindNode/Gin-24 1000000 1106 ns/op 23 B/op 1 allocs/op
// 增加了findNode的非递归版本,对比性能:
// 性能相比递归版本略有提升
//Benchmark_FindNode/TrieTree-24 599498 1819 ns/op 23 B/op 1 allocs/op
//Benchmark_FindNode/TrieTree2-24 667114 1547 ns/op 23 B/op 1 allocs/op
//Benchmark_FindNode/HashMap-24 5671921 213.0 ns/op 23 B/op 1 allocs/op
//Benchmark_FindNode/List-24 21 51678314 ns/op 24 B/op 1 allocs/op
//Benchmark_FindNode/Gin-24 956608 1123 ns/op 23 B/op 1 allocs/op
func Benchmark_FindNode(b *testing.B) {
// 初始化
b.StopTimer()
tree := NewTrieTree()
ginTree := &node{}
size := 1000_0000
m := make(map[string]bool, size)
l := make([]string, size)
for i := 0; i < size; i++ {
str := strconv.Itoa(rand.Int())
tree.InsertNode(str)
ginTree.addRoute(str, []HandlerFunc{func(*gin.Context) {}})
l[i] = str
m[str] = true
}
b.StartTimer()
// 开始
b.Run("TrieTree", func(b *testing.B) {
for i := 0; i < b.N; i++ {
str := strconv.Itoa(rand.Int())
tree.FindNode(str)
}
})
b.Run("TrieTree2", func(b *testing.B) {
for i := 0; i < b.N; i++ {
str := strconv.Itoa(rand.Int())
tree.FindNode2(str)
}
})
b.Run("HashMap", func(b *testing.B) {
for i := 0; i < b.N; i++ {
str := strconv.Itoa(rand.Int())
_ = m[str] == true
}
})
b.Run("List", func(b *testing.B) {
for i := 0; i < b.N; i++ {
str := strconv.Itoa(rand.Int())
for j, length := 0, len(l); j < length; j++ {
if l[j] == str {
break
}
}
}
})
b.Run("Gin", func(b *testing.B) {
for i := 0; i < b.N; i++ {
str := strconv.Itoa(rand.Int())
ginTree.getValue(str, nil, &[]skippedNode{}, false)
}
})
}
版权声明
 本文章由作者“衡于墨”创作,转载请注明出处,未经允许禁止用于商业用途
本文章由作者“衡于墨”创作,转载请注明出处,未经允许禁止用于商业用途
发布时间:2022年03月23日 14:26:17
备案号: 闽ICP备19015193号-1
闽ICP备19015193号-1
闽ICP备19015193号-1
关闭特效
评论区#
还没有评论哦,期待您的评论!
引用发言