



map 的使用
声明map
m := make(map[string]interface{}, 10)
// 声明同时初始化
m := map[string]interface{} {
"a": 123,
"b": "wee",
}
判断某个键是否存在
m := map[string]string {
"a": "a",
"b": "b",
}
if a,ok := m["a"]; ok {
fmt.Printf("a 存在:" + a)
} else {
fmt.Printf("a 不存在")
}
遍历map
m := map[string]string {
"a": "a",
"b": "b",
}
// 只遍历key
for k := range m {
fmt.Println(k)
}
// 同时遍历key,value
for k,v := range m {
fmt.Printf("%s:%s\n", k, v)
}
删除某个key
m := map[string]string {
"a": "a",
"b": "b",
}
delete(m, "a")
delete(m, "c")
for k,v := range m {
fmt.Printf("%s:%s\n", k, v)
}
有序遍历map
// 按指定顺序遍历
m := map[string]string {
"c":"c",
"d":"d",
"b":"b",
"a":"a",
}
keys := make([]string, len(m))
i := 0
for k := range m {
keys[i] = k
i ++
}
sort.Strings(keys)
for _,k := range keys {
fmt.Printf("%s:%s\n", k, m[k])
}
map 实现原理
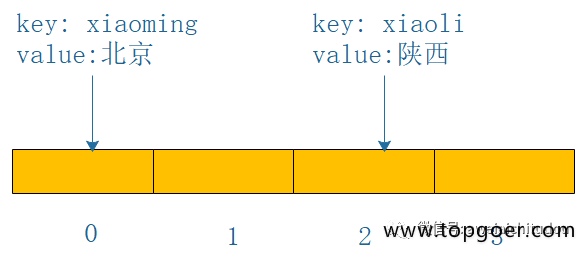
开放定址-线性探测
线性探测,字面意思就是按照顺序来,从冲突的下标处开始往后探测,到达数组末尾时,从数组开始处探测,直到找到一个空位置存储这个key,当数组都找不到的情况下回扩容(事实上当数组容量快满的时候就会扩容了);查找某一个key的时候,找到key对应的下标,比较key是否相等,如果相等直接取出来,否则按照顺寻探测直到碰到一个空位置,说明key不存在。
拉链法
拉链法:何为拉链,简单理解为链表,当key的hash冲突时,我们在冲突位置的元素上形成一个链表,通过指针互连接,当查找时,发现key冲突,顺着链表一直往下找,直到链表的尾节点,找不到则返回空
开放定址(线性探测)和拉链的优缺点
由上面可以看出拉链法比线性探测处理简单
线性探测查找是会被拉链法会更消耗时间
线性探测会更加容易导致扩容,而拉链不会
拉链存储了指针,所以空间上会比线性探测占用多一点
拉链是动态申请存储空间的,所以更适合链长不确定的
go map实现
https://cloud.tencent.com/developer/article/1468799
1.12在go中,map同样也是数组存储的的,每个数组下标处存储的是一个bucket, 每个bucket中可以存储8个kv键值对,当每个bucket存储的kv对到达8个之后,会通过overflow指针指向一个新的bucket,从而形成一个链表
当往map中存储一个kv对时,通过k获取hash值,hash值的低八位和bucket数组长度取余,定位到在数组中的那个下标,hash值的高八位存储在bucket中的tophash中,用来快速判断key是否存在,key和value的具体值则通过指针运算存储,当一个bucket满时,通过overfolw指针链接到下一个bucket。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//获取hash算法
alg := t.key.alg
//计算hash值
hash := alg.hash(key, uintptr(h.hash0))
//如果bucket数组一开始为空,则初始化
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 定位存储在哪一个bucket中
bucket := hash & bucketMask(h.B)
//得到bucket的结构体
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) +bucket*uintptr(t.bucketsize)))
//获取高八位hash值
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
//死循环
for {
//循环bucket中的tophash数组
for i := uintptr(0); i < bucketCnt; i++ {
//如果hash不相等
if b.tophash[i] != top {
//判断是否为空,为空则插入
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add( unsafe.Pointer(b),
dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize) )
}
//插入成功,终止最外层循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//到这里说明高八位hash一样,获取已存在的key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//判断两个key是否相等,不相等就循环下一个
if !alg.equal(key, k) {
continue
}
// 如果相等则更新
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
//获取已存在的value
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
//如果上一个bucket没能插入,则通过overflow获取链表上的下一个bucket
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/value at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
//将高八位hash值存储
*inserti = top
h.count++
return val
}
版权声明
 本文章由作者“衡于墨”创作,转载请注明出处,未经允许禁止用于商业用途
本文章由作者“衡于墨”创作,转载请注明出处,未经允许禁止用于商业用途
 闽ICP备19015193号-1
闽ICP备19015193号-1
评论区#
还没有评论哦,期待您的评论!
引用发言